




�����ǰ��һ���ڲ������У��漨��̳��ʼ��½��ֱ�ԣ����Ѿ������ϴ�ģ��ʱ���ġ���쭡��ٶ��ˡ�
��ChatGPT���������������£�ǧ�ڼ���ģ�͵ľ��������������ң�������ҵ���˶�ʽ�Ľ������ԼҵĴ�ģ�ʹ�������ܴ�ģ�͵������β�룬ȴ��һ��ڹ���ˡ����������ʱ䡱����ѧ���ɡ�
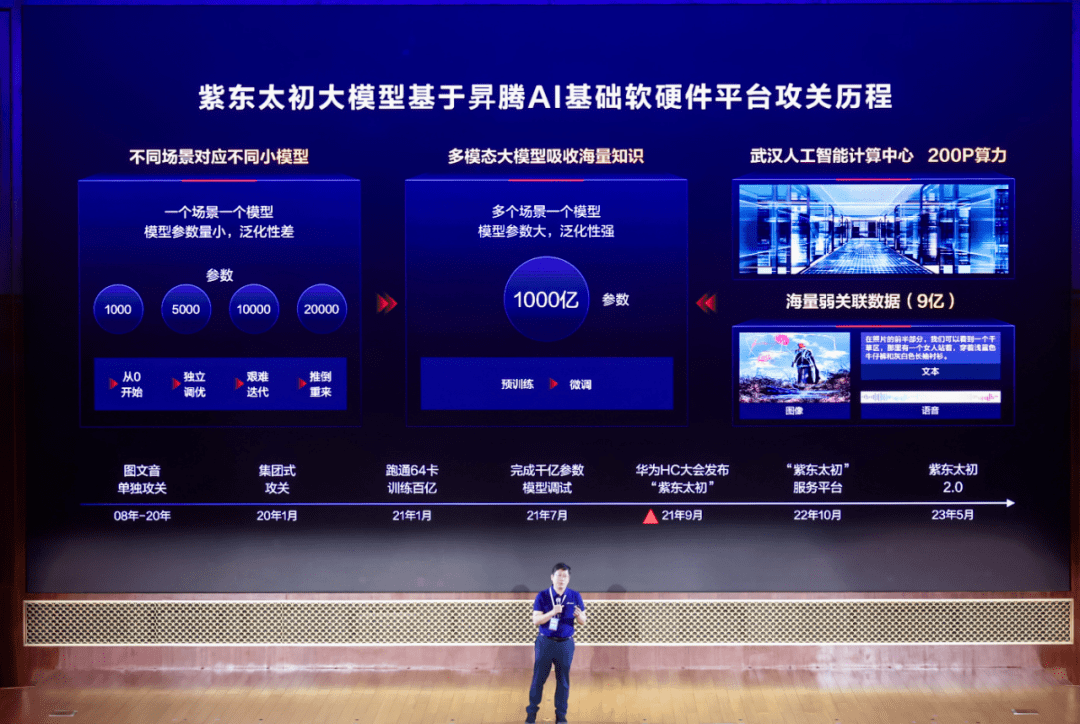
��ǰ�����ĕN��AI�����߷��2023�ϣ��й���ѧԺ�Զ����о������϶�.̫������ģ���о����ij������Ρ��人�˹������о�ԺԺ�����������ݽ��н����˻��ڕN��AI��N˼MindSpore AI��ܴ����ȫģ̬��ģ���϶�.̫��2.0�����״����ȫģ̬������ͳһ����ʽѧϰ��ܡ�
����Hugging Face���ϴ�ʼ��Thomas Wolf��˵�������ڹ�ȥ�ļ�����õĶ�ģ̬ģ��һֱ��������ͼ���ʵ���ҵ�ʥ����������ģ�ͽ��뵽ȫģ̬ʱ��������������ҵ��������ЩӰ�죿
�����ᵽ��ģ�͵�ʱ�������۵����������ǡ�����������1.1�ڲ�����GPT��1750�ڲ�����GPT-3��ǧ�ڼ������������˴�ģ�͵ġ����ż������Ͼ�ģ�͵IJ�����Խ�����Կ��ܾ�Խǿ��
��ʵ��������һ�ַ��������ģ̬���ֱ��Ӧ��ģ̬����ģ̬��ȫģ̬�Ȳ�ͬ���ͣ�����һ�����˵�GPT-3������ģ̬��ģ�ͣ��϶�.̫��1.0��GPT-4���ڶ�ģ̬��ģ�ͣ��϶�.̫��2.0��ȫ����ȫģ̬��ģ�͡�
�������еIJ�𣬿��Դ�����ά�Ƚ��в�⣺
������ԭ����
��ν��ģ̬������ģ�Ϳ��Դ������������͡���ģ̬��ģ��ֻ�ܴ���һ�����͵����ݣ�Ҳ�dz������ԡ��������Ӿ��Ȳ�ͬģ̬��ģ�͵�ԭ�����ڣ�����GPT-3ϵ�о�ֻ�д�����Ȼ���Ե�������
����˼�壬��ģ̬��ģ����ζ�ſ��Դ������ģ̬�����ݣ���������ģ̬��ģ���϶�.̫��1.0�����������ı���ͼƬ����Ƶ����ģ̬���ݽ��п�ģ̬��ͳһ������ѧϰ����Ӧ��ȫģ̬��ģ�ͣ���ָ���������ı���ͼƬ����Ƶ����Ƶ��3D�Ȳ�ͬģ̬�����ݽ��п�ģ̬��ͳһ������ѧϰ�����ӽ������ѧϰ��ʽ��
����dzɱ���
ChatGPT�ո��ߺ��ʱ������������OpenAI��ѵ���ɱ�����ϤGPT-3ѵ��һ�ε�Ӳ���͵����ɱ��ߴ�1200����Ԫ���ɴ˳���������һ������˵����ÿһ����ģ�Ͷ���һ̨����ġ��鳮������
�б��ڵ�ģ̬��ģ�͵��ǣ��϶�.̫��1.0�����Ķ�ģ̬��ģ�ͣ�ͨ��������������ģ̬��������ͳһ��ʾ��֧�����ֻ�������ģ̬���ݻ��ѵ�������������������ռ���ϴ�Ĵ��ۣ�����ȫģ̬��ģ�ͽΣ��϶�.̫��2.0��һ�������ص�����ȫģ̬�ͳɱ�Эͬ�Ż�ѧϰ���ܹ��ں϶�����ȫģ̬��������������ѵ���ɱ���
�����������
��ģ�������С��������漣������������Դ���ڴ�ģ�͵ġ�ӿ�֡�������ģ�͵IJ���������ij����ֵ��һ��˵���Dz������ﵽ600-1000�ڣ���ģ�ͻ����һЩ���벻���ĸ���������Ʃ�����������˼ά������������
����ǰ�����ᵽ�ģ��϶�.̫��2.0�״������ȫģ̬������ͳһ����ʽѧϰ��ܣ���ȫģ̬������롢�����������Ͻ����ѧϰ��ʽ���γ���ȫģ̬��������������ģ̬Ǩ�Ƹ�������֪ʶ��ȡ�����������µ��������϶�.̫��2.0������������ӿ�֣���һ��ͻ�Ƹ�֪����֪�;��ߵĽ������ϡ�
����ڱ�ƴ���������������ݵġ���ģ�������������ɵ�ģ̬����ģ̬�ٵ�ȫģ̬�Ľ����������Զ�ѧϰ�����ӵ�������ģʽ��ʵ�ָ�ȷ����Ч��Ԥ��;��ߣ�ͬ��������ͨ���˹����ܵı���֮·��
���˵��ȫģ̬�����϶�.̫��2.0�ĵ�һ������㣬��һ��ֵ�ù�ע����Ϣ�ǣ��϶�.̫��2.0-3.8Bģ���Ѿ��ڕN˼MindSpore������Դ��������϶�.̫��1.0��֧�ָ�ϸ���ȵ�ͼ��ʶ�𡢸���֪ʶ���Ӿ��ʴ𡢸��ḻ��ͼ��������
�ƺ��б�Ҫ�����¿�Դ�ͱ�Դ�Ĺ��¡�
1997�꣬�����ڿͰ���ˡ�˹�ٷҡ������ڡ���������м���һ����Ԥ�������ֲ�ͬ��������������ģʽ��һ���Ǵ����ģʽ��ԭʼ�����ǹ����ģ���ÿ���汾�Ŀ���������һ��ר�����Ŷӹܿأ�һ�����м�ģʽ��ԭʼ����ͬ���ǹ����ģ������Ƿ��ڻ������Ϲ��˼��Ӽ���������ֱ�ӵ����Ӿ���Linux��
���ա��м�ģʽ��֤���˿�Դ�ȱ�Դ���Ӹ�Ч��ȫ��99%����֯��ITϵͳ��ʹ���˴����Ŀ�Դ���룬��Դ�ļ�ֵҲ��Խ��Խ�����ҵ���ӡ�

2020����ǰ��ʱ��OpenAI�ŷ��Ҳ�ǿ�Դ���ԣ�������ҵ������ջ��£�GPT-3ѡ���˱�Դ��ֻ��Կ������ṩAPI��OpenAI�ɴ˱�Ϸ��ΪClosedAI�������ڹ��ڵļ��Ҵ�ģ�ͳ���Ҳѡ����APIģʽ��
���������϶�.̫��ϵ�д�ģ���ڕN˼MindSpore������Դ����ʵ���壬���������ҵ�һЩ��ͬ�Ĵ𰸡�
һ�Ǽ۸���档��Դû����ν�����ɻ�ʹ�÷ѣ�ֻҪ���㹻�����������ݣ��Ϳ����ڕN˼�����������϶�.̫��2.0-3.8Bѵ���Լ��Ĵ�ģ�͡�����Դ�ijɱ�ȡ���������Ĺ�ģ��ĿǰOpenAI��ChatGPT API�����½ӿڵ��÷���ÿǧ��tokenԼ0.002��Ԫ���ۺ������0.014Ԫ�����Ƕ�ν��۵Ľ����
���ǰ�ȫ���档��Դ������һ�������������������룬����Դ���ɵ�һƽ̨������©���������˴������������ʱ���������Ҵ�ģ�͵İ�ȫ����Զ��ֹ�ڴˣ��ݴ����ǵ�������ChatGPT����20��ʱ�䣬���س��л���������й������������ֹԱ��ʹ��ChatGPT��Google Bard��Bing������ʽAI���ߡ�
���Dz�ҵ���档��Դ������������һ����ԣ��������ڴ��룬��Ϊ��Դ�����ľۺϺͷŴ�ЧӦ�ȿ�Դ������м�ֵ���ر��Ƿ���δ���Ĵ�ģ������Դ�ı�����Эͬ�ʹ��£�Эͬ��ȫ�������п�Դ��������Эͬ��������һ�������Ĵ��£�����ڸ���Ϊս�ı�Դģʽ����Դ�����ڲ�ҵ��̬�������ͷ��١�
�϶�.̫��2.0������Դ��ͬʱ��ͬ���������϶�.̫�����ŷ���ƽ̨������֧�ֹ����ơ�˽���ơ���������ڵĶ��ֲ���ʽ�����ݕN�ڡ�Ӣΰ�AMD��Ӣ�ض��Ȳ�ͬAIӲ������ΪAI��ܵĕN˼MindSpore���ṩ���������ġ�ѵ�����ġ�ģ�����ġ������������ڴ�ģ����������һ�������˴�ģ�͵Ŀ����ż�����ͨ��һ��ʽ�����Ͳ������ŵ�����˿���Ч�ʡ�
ȫģ̬��ģ�͵ġ��������������ڿ����߶��Բ���ң���ɼ���
Ҳ�����ֽζ��ԣ�����Ϊ��Դ�ͱ�Դ��ʤ���¶��ۡ��ɶ��ں�����ģ�͵�ǧ�����ҵ��˵���Ȳ���ʽ����Ҫ����ʵ����أ������ģ�͵���������ת��Ϊ��ҵ��ֵ�������õĹ���Ҳ������ĭ��
�����ڶԻ�ʽ������������ӿʱ�����ٴ�ģ�Ͳ�δ���ڸ�������Ϊ��ģ������IJ������Ƕ��������������ʵ�ش������չ�ᱻ��쭵ij�����ѹ����ҵ��ز��Ǵ�ģ������������ĭ�������ɡ�
��ȷ��һЩ�Ļ�����ģ��ͨ���ڴ��ģ�ޱ�������Ͻ���ѵ������ѧϰij�������������ڴ�ģ�Ϳ���Ӧ��ʱ��ֻ��Դ�ģ�ͽ��������Ϳ�����ɶ��Ӧ�ó������������˵��ȥ��AIӦ���ǡ��ֹ�������ʽ�ģ��ڴ�ģ�͵������£��˹����ܵIJ�ҵ�������������ˮ�ߡ�ģʽ�ݱ䡣
���ٻ��ڕN˼MindSpore AI��ܵ��϶�.̫����ģ���Ѿ�ӡ֤����һ�㡣
���������ߺ����û����人�˹������о�Ժ�Ƴ��ˡ���������AI���ݴ���ƽ̨��ͨ���϶�.̫����ͼ��������������ģ̬���������������������ܹ��Զ�����AIGC��ѵ�����ݣ�ͨ���ı���������ͼƬ��ϸ������Ϣ���п��ƣ�����ͷ������ɫ������ı��顢������Ч�������Ķ���ȵȡ�
ͬ��ƽ̨��Ҫ��������ʾ�ʲ���ȷ��ͼʱ�������������Ѿ�ͨ����Ȼ����ʵ���ˡ�һ��ɻ����������϶�.̫��2.0���Ӿ�֪ʶ���������ɣ����ų���������ͼ���ġ�ͼ�����ʶ��ȸ��Ի������淨��
�ٱ���������ҵ�Ķ�ģ̬�˹����ܲ�ҵ�����壬Ŀ�������ϲ�ѧ���ø�����Դ�������ģ̬�˹�������ҵӦ�ã�̽��ͨ���˹����ܲ�ҵ��·����Ŀǰ�Ѿ��л�Ϊ���й��ƶ�������������66λ��Ա�������С�

ֱ�ӵ����Ӿ��Ǵ�ģ�������������е�Ӧ�á����ڡ��϶�.̫������ģ̬��ģ�ͣ���������������Ԫ����ĸ���������YYDS���������ˡ����������������������IJ�ͬ����YYDS�������û������Լ������˵�������������������Լ�ר�����������֣�ʵ����ǧ��ǧ��ĸ��Ի��������㡣
�����ҵ��İ������кܶ࣬�����϶�.̫��2.0��ģ�����ǻ۷��ɡ��ǻ۽�ͨ���ǻ������ǻ�ҽ�Ƶȳ����е�������ء�
���������ȫģ̬��ģ�͵���ȷ��ʽ�����ڴӹ�ȥ�ġ�һרһ�ܡ���ר���ܡ����ɡ��ڕN˼MindSpore�ȿ�Դ�������ƶ��£���ģ�Ͳ�����������ͨ������ʹ��AI��������Ҳ������ǧ�а�ҵ���ܻ�ת�͵ľ��롣
��������Ļ����϶�.̫��2.0�����Ľ���ֻ�ǡ�ȫģ̬��ģ�͡����Ⱥӣ�һ������ؿ����ֵ�IJ�ҵ�������������Ļ��
��ʹ��2018��OpenAI��GPT���𣬡�������+��ģ�͡�����ҵ����Ҳ�����Ž���������ͷ���ڼ�����д��ۣ�������ʽ�����Ѿ���ע������ʵ��
�����ı���ͼƬ����Ƶ�����ݵĻ����ϣ���һ������3D����Ƶ�������źŵȶ�ģ̬���ݵ��϶�.̫��2.0��ע���˴�ģ�ͽ���֮·����ת�۵㣬ͨ���Ż���������Ƶ���ı����ں���֪�Լ���ʶ����ȹ��ܣ��������˹����ܴӸ�֪�������Ϊ��֪���磬���������ǿ���ͨ������������ˢ�����ǵ�����ռ䡣
