商业智能在CRM中的应用
本文以企业管理信息系统为基础,从探讨CRM本身的特点出发,结合数据挖掘的原理、SQLSERVER2005的BI平台中的分析服务和报表服务,进行一个实例的分析。对CRM系统的一些关键性领域存在的问题,提出期望的解决方法。

一、背景思考
(一)商业智能概述
商业智能(Business Intelligence,简称BI)的概念最早是Gartner Group的Howard Dresner于1996年提出来的。商业智能概念涵盖了查询报表、数据分析、数据挖掘、数据备份和恢复等所有以帮助企业决策为目的的技术及其应用。
商业智能的关键是从实际的营运数据中,进行数据预处理,然后抽取(Extraction)、转换(Transformation)和装载(Load),即ETL过程,利用各种技术或工具,最终得到一个企业级的决策信息。
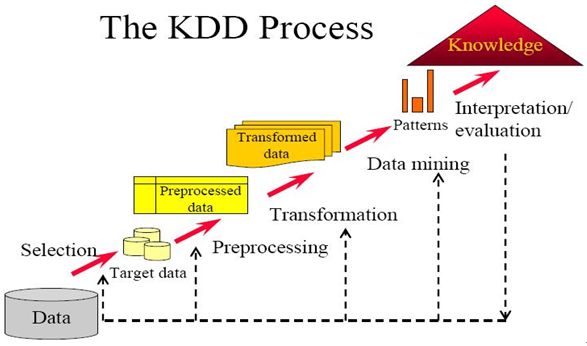
对于零售行业的决策信息获得,通过一个比较形象的,更贴近我们零售企业日常应用的过程来表现,即数据库的知识发现(Knowledge Discovery in Database,KDD )。而在科研中称的“知识发现”,在工程领域也常被称为“数据挖掘”。
下图展示了知识发现的过程:
(二)CRM概述
在布赖恩•伍尔夫的基础性研究《Measured marketing》中描述到,统计中发现消费额在前30%的顾客贡献的消费额是75%,而消费额后30%的顾客贡献的消费额仅仅是3%。这足以说明顾客在购买能力上的不均等性。以顾客为中心的零售经济学的宗旨是让顾客满意,将企业的有限的资源投入到最有价值的顾客身上,为自己的忠诚顾客提升更有价值的服务。这和零售产出管理是异曲同工的。
而对于一个客户关系管理系统,其主旨也在于帮助企业通过技术手段,分析客户的行为和他们的价值,以提供更优的消费服务及客户体验。
通常,CRM系统分为分析型、运营型、协作型。对于一个零售企业的客户关系管理系统,通常是以各种介质的卡作为载体去绑定顾客的身份,从而贴近顾客,服务顾客。所以对于一个零售企业的客户关系管理必然会涉及到卡管理,同时涵盖客户分析和沟通等。
通常对于数据分析的需求,可以分为:
1、客户概况分析:客户的层次、风险、爱好、习惯等;
2、客户忠诚度分析:基于类别管理,考查客户类别转移和变节,及考查经济忠诚和关系忠诚;
3、客户利润分析:不同客户所消费的产品的边缘利润、总利润额、净利润等;
4、客户性能分析:不同客户所消费的产品按种类、渠道、销售地点等指标划分的销售额;
5、客户未来分析:寻找客户数量、类别等情况的未来发展趋势,以争取客户;
6、客户产品分析:主要针对商品的关联分析,及涉及的供应链优化;
7、客户促销分析:包括邮报或降价等促销活动的管理。
二、应用实例
(一)顾客类别管理
本实例的目的是创建一个简单的顾客分类,在顾客分类的基础上,进行相应的商品品类购买的分析。
基于顾客类别管理的理论,不可能在分析时直接针对单一顾客进行分析,肯定是对同一类别的顾客,进行相应的消费行为习惯分析等。这就如同商品要进行品类管理的道理一样。当只有进行顾客的类别管理时,才能去考查类别人数转移量,这是会员管理成效的一个重要指标。也只有这样,才能对变节率等指标进行
考查。
我们通常进行的顾客分类,都是利用客单量或购物频次划一根线,来界定分类的象限。而真正的顾客聚类,通常考虑了客单、频次或者收入等等综合因素而实现。通过简单的划线式分类,无法达到“人以群分”的效果。
(二)聚类分析
聚类算法有能力发现用来对数据进行分组的隐性变量,因此对于零售行业来说,聚类算法是一种非常流行的数据挖掘技术。
对于聚类算法来说,常用的有两种:K-平均和K-中心点。
在SQLSERVER2005 BI Development Studio中的聚类算法也有两种,K-means算法和EM算法,这两种都是属于K-平均算法的。
K-means算法是以距离值的平均值对聚类成员进行分配,每个对象是在一个聚类中,聚类和聚类之间互不重叠, 通常被认为是硬聚类。而EM算法试用概率进行度量,一个点可能属于多个聚类,每个聚类有不同的概率,聚类之间是可以重叠的,通常被称为软聚类。对于离散属性的聚类是适合使用EM算法的。
Microsoft的聚类算法有一个可收缩原理,对于一个可收缩的框架,当进行重复训练时,对于不会在聚类之间移动的数据,都把他们压缩,不加载到内存,这样就压缩了内存空间。
SLQ Server Analysis Services有两个主要的数据挖掘对象:挖掘结构和挖掘模型。挖掘结构用来定义挖掘问题的对象,而挖掘模型是挖掘算法对挖掘结构的具体应用。
本节中下面的例子,是在SQL Server Analysis Services服务的平台上,新建的一个analysis services项目, 应用可收缩的k-means聚类算法模型,以某大型超市近半年的会员消费数据基础,只通过客单量和频次两个维度,对会员进行简单分类。总共分成了4类会员。在后面报表应用时,将简单的以A、B、C、D来标识。首先如下图显示:
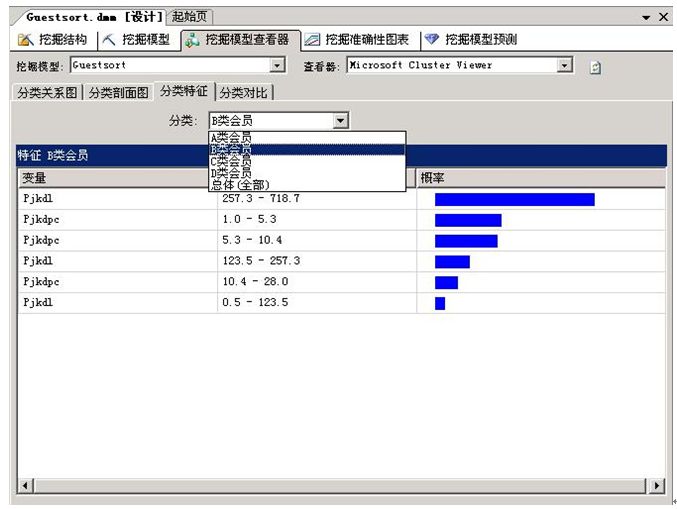
需值得注意的是,在进行数据预处理的时候,须先进行数据的清洗。将一些垃圾数据清除,将需要的数据进行加工。
对于SLQ Server Analysis Services的挖掘结果的发布,可以直接通过DMX语言进行查询,或者通过SQLSERVER2005 BI Development Studio来创建报表模型来展示。报表模型的使用在下一节中叙述。这里先说明下DMX语言的使用。
数据挖掘扩展插件 (DMX) 是一种语言,在 Microsoft SQL Server 2005 Analysis Services (SSAS) 中可以使用该语言创建和处理数据挖掘模型。可以使用 DMX 创建新数据挖掘模型的结构、为这些模型定型并对其进行浏览、管理和预测。DMX 由数据定义语言 (DDL) 语句、数据操作语言 (DML) 语句以及函数和运算符构成。譬如在上例中如何找到哪些是“B类会员”的:
SELECT t.cardcode From [Guestsort] PREDICTION JOIN OPENQUERY([Hd31],
'SELECT [cardcode],[pjkdl],[pjkdpc] FROM [dbo].[guestsort] ') AS t
ON [Guestsort].[Pjkdl] = t.[pjkdl] AND [Guestsort].[Pjkdpc] = t.[pjkdpc]
where Cluster() = 'B类会员'
当然如果不想这部分会员的分类叫“B类会员”,而改称为“白银会员”或其他称呼,那么也是可以通过DMX语言来修改挖掘模型的内容得到。
(三)报表发布
上一节提到了发布数据可以通过Reporting Services来展示。Reporting Services提供了一个创建定制报表的机制,这个报表通常包含文本和图形,可以通过HTML、Email、打印形式和Microsoft Office文档发布。基于Web的报表可以是交互式的,通过增加报表参数实现交互目的。
本节中下面的例子,是基于顾客类别管理的基础上,对A、B、C、D不同类别的顾客所关心、购买的商品品类进行的统计分析。如果将这个过程进一步细分的话,那就是针对商品级别的关联规则的应用,这个在这里不进行讨论。这里只是通过商品品类和会员类别的矩阵式展示,较简单地体现Reporting Services的功能。
同样在SQLSERVER2005 BI Development Studio可以去创建一个Reporting Services项目。数据源可以是关系数据库,也可以是Analysis Services等。具体的过程不描述了,从数据源中最终的报表文本或图形等,进行生成、部署,最终可以通过web的方式进行浏览。 下图示意了一个简单数据的发布: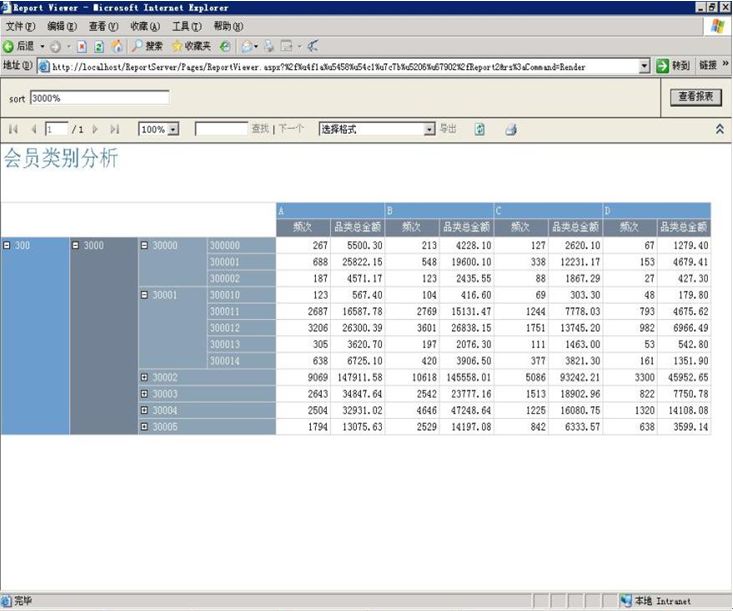
通过web展示的矩阵格式,行代表商品类别,列代表会员类别,以显示不同类别会员对不同品类商品的购买情况。
同时上图也示意了一个交互的过程,可以通过用户指定的商品类别来查看感兴趣的数据。比如查看中类3000的商品被A、B、C、D四类会员的购买频次及品类金额情况。当然也可以增加其他的查询条件。
对感兴趣的类别支持树形结构的自由展开,下钻到小类,子类。如上图的30000小类和30001小类就展开明细到各自的子类中。
对于报表的结果可以导出到XML,HTML,PDF,EXCEL等等文件中。
报表平台支持同时也支持对各种角色的权限管理及日常的订阅服务等。
三、应用前景
从目前的实际应用来看,聚类分析作为数据挖掘的一种算法模型,还有很多需要值得去调整的地方,譬如:如何数据预处理,如何剔除大型促销等,造成的数据异动……
而对于CRM本身的7大分析需求,也需要更多地挖掘模型进行实践。比如考查顾客类别转移时,可以使用序列聚类算法。产品分析时,可以使用关联规则。而对于同一种业务场景,应用不同算法也将得到不同的结果。因此可以通过挖掘准确性图表,对挖掘模型本身进行不断的修正。
可以预期在未来的应用过程中,结合商业智能理论的应用,通过顾客关系管理,将为顾客带来更美好的消费体验,给零售商带来更多的销售提升。
